If you spend a good amount of time on the computer, you probably interact with databases several times a day—if not several times per hour.
Databases power everything from banking software to scientific research to government records, as well as the websites you use every day, like Amazon, YouTube, Netflix, and Wikipedia. In fact, if you found this page through an Internet search engine, your search was powered by a (very, very large) database.
But databases aren’t just for massive websites that serve millions of users per day—they can also be used by small businesses, or by a small group of people.
The reason why databases are so common, for use cases big and small, is because they make accessing information using a computer much, much easier.
If you work with information on a daily basis—and most of us do!—it’s worth understanding what databases are. And once you understand what databases are, you might even want to build your own databases, which will work just the way you need them to.
What is a database?
A database is a logically organized collection of information, designed in such a way that the information within can be accessed for later use by a computer program.
Here’s another way to think about databases: a computer is a device that allows you to manipulate information, whether that information takes the form of words, numbers, pictures, or videos. However, a computer needs to store the information before that information can be referenced or changed, and it also needs to ensure that you can find the right information at the right time. Databases are how computers solve these two problems.
By definition, the data within a database needs to be arranged according to a consistent, logical set of underlying principles. The term data model describes the logical structure of a database, which determines the rules for how the information within can be organized and manipulated.
There are many different types of databases, which are usually classified according to their underlying data models. For example, the most popular data model, the relational data model, organizes information into related two-dimensional tables, whereas the graph data model organizes information into nodes (points) and edges (the lines connecting those points).
Different data models have different benefits and drawbacks depending on what you’re trying to accomplish. If you’re trying to create a database with a high degree of data integrity that can scale flexibly, a relational database will likely work best; if you need a database that can handle massive quantities of data, a graph database could be a good option.
Is the data you’re handling mostly structured, or unstructured? When data is structured, that means it’s formatted and searchable—think of a list of customer names and emails in a spreadsheet or CSV. Unstructured data lacks both formatting and accessibility, and is therefore much harder to analyze. The most common examples of unstructured data include audio, video, and image files.
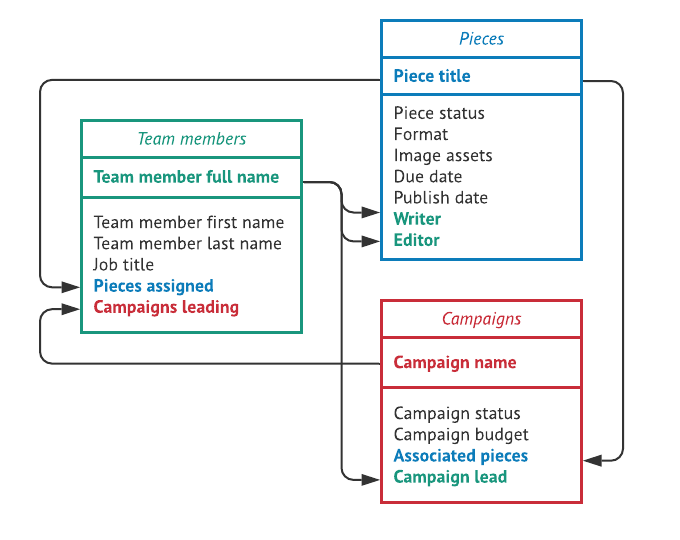
No matter what type of data you’re working with, it needs to be organized according to a database schema. You can think of a schema as a blueprint for a database, describing details about how you want the database to be implemented—like required data types or other constraints.
The schema of a database is what distinguishes it from a list or a spreadsheet: with a schema, you can rest assured that the data inside your database will be organized according to a certain set of rules, because it must be.
Once organized, you still need some way to interact with the database in order to perform your desired actions. A database management system (commonly abbreviated to DBMS) is the software that makes it possible for end users to create, modify, and manage databases, as well as define, store, manipulate, and retrieve the data inside those databases. Some examples of database management systems include MySQL, MongoDB, Oracle, FileMaker, Microsoft’s Azure, and Airtable.
Within a database management system, you’ll find different database applications that help you retrieve and manipulate the information that lives in your database.
As with data models, the right DBMS for you will depend on your goals, technical capabilities, the type of data processing you're doing, and available resources.
What are the benefits of a database?
Even knowing what databases are, and knowing what crucial services rely on databases, you still may be wondering: “Why bother with a database?” What makes a database better than a list of information?
When is a database more useful than a spreadsheet? Why is a data management system so critical? Different kinds of databases and database software offer different benefits, but there are shared features of all databases that make them incredibly valuable for managing data:
- Databases can scale as your business grows
- Databases can handle multiple users with ease
- Databases store information accurately and reliably
- Databases allow you to avoid redundant information
- Databases can process your data in powerful and interesting ways

Databases are scalable
Database systems are capable of storing and handling truly massive, complex data sets, or big data. This is why websites like Google that have to deal with terabytes (and even petabytes) of data every day need databases in order to function.
You might not be dealing with terabytes of data on a day-to-day basis—yet. But the fact that databases are capable of handling large amounts of data means that a well-designed database can last you for many years as you accumulate more data over time. Your business is only going to grow, and investing in a database that can grow with you will save you and your database administrators from future headaches.
Databases vs. spreadsheets: scalability
Imagine that you’re running an online clothing brand, and you want to keep records of every order that gets made, from request to fulfillment. If you have a small-scale operation and you’re only fulfilling one or two orders every day, it might seem simple enough to start by keeping track of order information in a spreadsheet.
However, if the volume of orders increases—maybe your brand gets more popular, you hire more staff, open physical stores, and start tracking metadata from your website. The sheer quantity of information will start to strain your spreadsheet, and your computer or website might experience sluggishness or even freezing.
Performance issues in your spreadsheet will only compound over time if your business keeps thriving for multiple years. In contrast, databases have far greater storage capacity and are designed to work long-term.
You could try and address the problem by storing your order information in multiple spreadsheets—but this makes it harder to find the information that you need, and creates issues with data redundancy.
Databases can handle multiple users
Databases become an even more powerful tool when you need to collaborate with other people: unlike spreadsheets or lists, databases are designed from the ground up to support multiple people working together and taking action on a shared set of information. Database management systems also have built-in mechanisms to ensure that data stays consistent even if multiple people are accessing the same data—so you won’t have situations where one person tries to make a change that conflicts with a different change that someone else tried to make at the same time.
Furthermore, most database management systems also give you options to control who can access different kinds of information, as well as who can change it.
Databases vs. spreadsheets: handling multiple users
Returning to our clothing brand example—as your company grows, you find that you need to bring more staff on to scale up production. If you’re managing your business on traditional spreadsheets, only one person can access and make changes to a file at any given time, making it hard for all employees to stay on the same page. The situation gets even worse if different employees work from different versions of the same spreadsheet, which become increasingly dissimilar over time.
Newer cloud-based spreadsheet programs can avoid some of the issues related to versioning and conflicting changes. But they also usually lack the granular access controls that, for example, a cloud database would offer.
Databases are reliable
Errors in your data can be extremely costly, and in worst-case scenarios can even make your data useless. Fortunately, the fact that databases have a defined structure, as well as access controls, make it much easier to prevent human error.
Databases also have built-in mechanisms to safeguard against data loss, and to restore data if you need to roll back changes.
Databases vs. spreadsheets: reliability
Since a spreadsheet has no schema in the way that a database does, there are fewer rules regarding where and how users can input data—which means that, over time, human errors are likely to accumulate in your spreadsheet, especially if you have many humans trying to use the same spreadsheet. It’s very easy to accidentally mistype a product code, or type the right information but into the wrong cell.
No matter how good you might be at your job, mistakes can and do happen. Fortunately, with a database, any new data or changes to existing data have to abide by certain rules, so you can prevent mistakes from happening in the first place.
Databases avoid redundancy
The purpose of a database is to make information easily accessible for later use. One way in which a well-designed database can make this happen is by ensuring that each piece of data only exists in one location at a time. If you wanted to find out the answer to a specific question, such as “What is this person’s phone number?” or “What is the retail cost associated with this particular product code?” wouldn’t it save you time if you knew that you only had to look in one place to find a definitive answer?
This becomes even more critical if your workflow is one in which you need to update data on a regular basis. With a database, you can update information in one place and rest assured that any other places in which that data is referenced will be automatically updated as well—rather than scouring your files manually to try and find instances of the old, outdated data.
Databases vs. spreadsheets: redundancy
Suppose that every e-commerce order you add to your store’s order spreadsheet also has the customer’s contact information associated with it. What if you wanted to mail all your VIP customers special swag?
One way you could try and do this is by making a separate spreadsheet devoted specifically to collecting customer contact information. If you do this, however, you’ll have the same customer contact information living in multiple places.
If a customer changes their shipping address, that means you’ll need to manually update that information in multiple places—leaving your business open to potential errors if you forget to do this manual work, or if you accidentally copy and paste the wrong information. You might even end up sending an order to the wrong location! Redundancy costs you valuable time by creating unnecessary busywork, but perhaps more importantly, it also leaves you vulnerable to mistakes.
Databases are powerful
Since databases are designed to make it easy to retrieve data, they also make it possible to process that data in powerful and interesting ways. Essentially, you can ask—or “query”—your database in order to try and answer specific questions, like “How much of this kind of product was sold in this specific timeframe?” or “How does paid search advertising compare to partner referrals when it comes to acquiring new customers?”
When you query a database to try and answer a specific question, you can store the results of that query as a view, which, in the database world, is a defined subset of the database you can reference later. By narrowing the scope of available information, views help people who are working with the database to more easily find the relevant data that they need in order to accomplish their work. Additionally, most databases allow you to control access to these views with granular permissions, which means you can ensure that only the right people can see your data.
Historically, many databases have required that you learn specific kinds of computer languages in order to query your database. For example, one of the most widely known languages is SQL (an acronym for “Structured Query Language”), which is used for many relational database management systems.
However, these days, there are several database systems—including Airtable—that come with more intuitive graphical user interfaces (GUIs) built in, allowing even the least experienced beginners to start using real-time information from databases to make better business decisions.
At their core, the purpose of databases is to make working with information easier. Most people spend their work (and lives) in situations where managing information effectively is of the utmost importance.
A cattle rancher, for example, needs to be able to manage information related to their herd, like each cow’s weight and vaccination history. The head of operations at a cybersecurity company needs to check the data security on all assets coming through a production pipeline. A product manager needs to give database access to some members of his team (but not others) and compare price points from multiple vendors.
Although you probably store data and interact with databases every day, using databases to make real-world decisions can still seem pretty daunting. Never learned Python or JavaScript? Never fear. You don’t need experience with programming languages in order to understand the basics of databases and start reaping their benefits. And a low-code approach to solving business problems lets you move faster, scale more quickly, and build a data management system that will grow as your business grows.
If you’re interested in seeing hundreds of examples of how people use databases for everything from marketing and video production, to nonprofit management and product planning, to UX research and sales, check out Airtable’s extensive gallery of free database templates. Additionally, if you want to learn more about switching to a database, you can download our How to Switch from a Spreadsheet to Database e-book for free!