A relational database is a collection of data logically organized so the information can be easily edited, added to, deleted, and most importantly, accessed. Relational databases, which store data in structured tables, are one of the most popular and easy-to-use types of databases.
You might be familiar with traditional spreadsheets, which also store data in tables. However, unlike spreadsheets, which were originally developed to function like accounting worksheets for financial calculations, relational databases were specifically designed to make data storage reliable and scalable. Because of this, relational databases offer vast flexibility in terms of what you can do with information.
Databases were once mainly used by developers, who pulled information out of them with a programming language, SQL, for Structured Query Language. Query languages are still around (developers made more, like open-source mysql). Those who know query languages can still use them to work with database information.
But now, you don’t need to know SQL or any other language to be able to use a database well.
Once you understand the components of relational databases, you can begin to envision how to construct and use them for your particular needs.
Perhaps you’re building a simple record-keeping system that will help eliminate mistakes, or diving into a big-data project for a large team. Maybe you’ve been tasked with pulling information into a company system via an API or designing a relational database management system (RDBMS) for your company. A good working knowledge of databases will help in all these cases.
Let’s start at the top.
A database is the container for all your data. (In Airtable, we call it a base.)
Look inside a database, and the first thing you’ll find is at least one table.
What is a table?
Tables are the main building blocks of relational databases. Each table is a data set composed of records and fields, and represents a single subject.
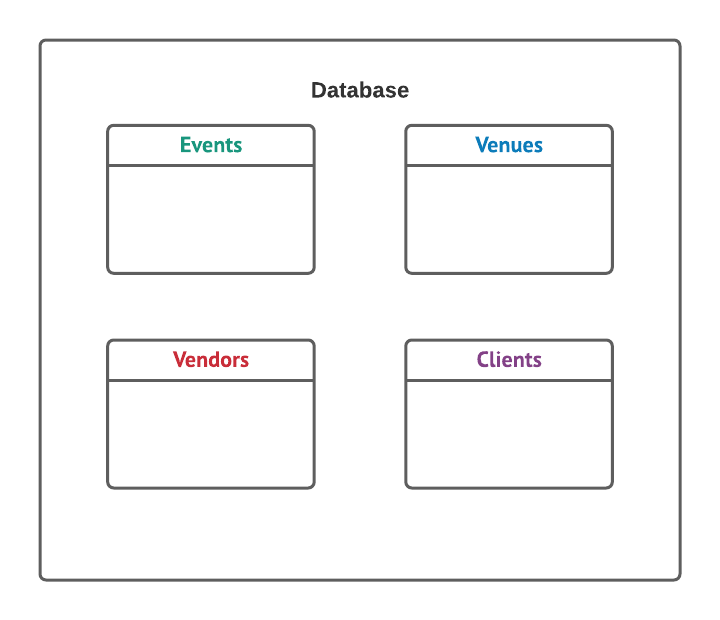
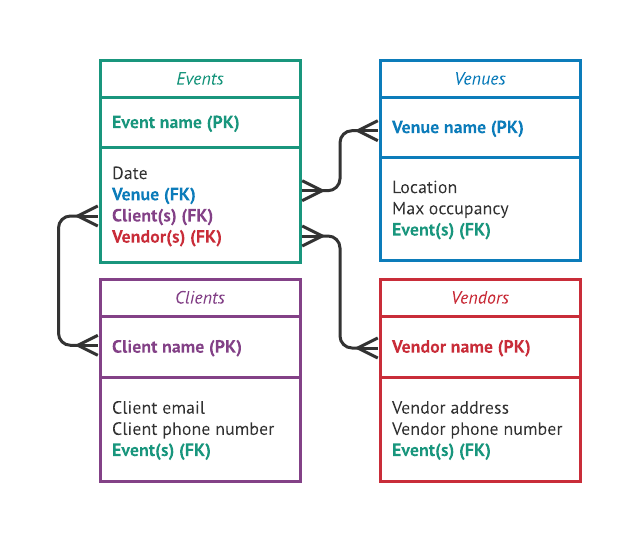
For instance, if you’re an event planner, you might have a table for events, a table for venues, a table for vendors, and a table for clients. Each of these tables contains all of the relevant data for that specific subject: for example, the event table might contain dates and times for each event. Inside a table, the data is arranged into records and fields.
Nerd alert: the technical term for a table in a relational database is "relation." In 1970, while working for IBM, Dr. Edgar F. Codd first proposed the relational database model in a paper titled “A Relational Model of Data for Large Shared Databanks.”
His relational data model was heavily based on mathematical set theory, and the name “relation” for a table is based on terminology from this set theory. A common misconception is that the term “relation” comes from the fact that the tables in a relational database “relate” to each other.
What are records?
In a relational database, a table represents a single subject; a record is a unique instance of that kind of subject. For example, in an event planner’s database, each record in the events table represents a different event (“The City Museum 15th Annual Fundraising Gala,” “Equilux Holiday Party,” etc.); each record in the vendors table represents a different vendor (“Objectively Edible Catering,” “By the Bouq Flowers,” etc.); and so on.
Nerd alert: Any mathematicians in the house? You might know records by another name: tuples. A tuple is a finite ordered list of elements.
If you’re familiar with traditional spreadsheets and their grid format, you might think of records as “rows,” and records are in fact often visually represented as rows in a grid. However, there are two key difference between rows in spreadsheets and records in relational databases:
- The order of the records within a table in a relational database does not matter. This means that a relational database can give you a lot of flexibility when it comes to how data can be displayed. You can reorder records, look at a specific filtered subset of records, or even visualize your records as calendars, charts, or kanban boards: no matter how you choose to look at the records, the underlying data in the table remains the same.
- Every record in a relational database must be identifiable by a unique value. Because every record is uniquely identifiable, you can avoid duplicate data, and just reference that single unique record whenever you want to get data on a specific subject.
These two facts are what make a relational database capable of representing the relationships between different people, objects, and ideas. Records can be added, deleted, and modified, and when a change is made to a record, it shows up everywhere that record is being referenced.
Think about a database that includes customer information. You use this information in various places within your business operation.
For instance, you probably use this type of data management for marketing, where it’s important that email addresses are correct. You may even go so far as to target your marketing to each customer’s state. A customer who has made a purchase or is actively enrolled in a service sees a different marketing campaign than a prospective customer might.
It’s therefore important to know when a customer’s state changes—for instance, if they make a first purchase. That customer’s data points are also used by your fulfillment operation and your billing operation, so one record is pulled into multiple places.
Within a database, customer records are updated as needed—sometimes automatically, when a certain action occurs, such as a purchase. Anywhere that customer information is referenced, the change is instantaneous.
As you gain and lose customers, and as customer information changes, it’s updated in real-time everywhere you use it. The same goes for any kind of information you transact with in your business. This general principle, which also involves backing up the database so all transactions are logged, is known as durability.
What are fields?
In a relational database, a field represents a characteristic of the subject of the table. For example, in an event planner’s database, the “Venues” table might include fields like “Street address” and “Maximum occupancy,” whereas the “Vendors” table might include fields like “Vendor type” and “Vendor Phone Number.”
When a table is displayed as a grid, the rows are records, and the columns are fields. Another way to think about records and fields is that records are like nouns, and fields are like the adjectives that describe those nouns.
Nerd alert: to be precise, fields are referred to as attributes by engineers.
Relational databases allow you to create rules for what kind of data can be entered into each field of a record—you can’t, for instance, put words into a field designated for numbers, or put an invalid email address into a field designated for email addresses. Holding information in fields and records rather than static rows in a spreadsheet makes it much easier to work with and keeps data integrity intact everywhere.
What are keys?
Here’s where it gets exciting. In a relational database, there are special types of fields called keys. Keys connect the dots: they create relationships between records across multiple tables.
Primary keys
Within a table, the primary key field—or as we call it at Airtable, the primary field—holds a unique identifier ID for each record. The primary field cannot be deleted, and must contain unique information. For this reason, it can’t be formatted as a checkbox or a select field. It must contain a unique identifier—words or numbers.
Foreign keys
A foreign key field is a field within one table that points to the primary key field of another table. For instance, in your table of customers, you might have a field containing a unique identification number for each customer, and that ID number will be the primary key field of the customers table. When that ID number is pulled into another table—such as a customer orders table—it shows up in that table as a foreign key field.
What are the different kinds of table relationships?
The primary and foreign key fields create relationships between database tables. To say that tables are related is to describe how they share information. When information is updated in a record, it’s automatically updated in every table that displays that information.
With databases, the relationships between types of information can take a few different forms. There are three ways of describing such relationships.
One-to-one relationship
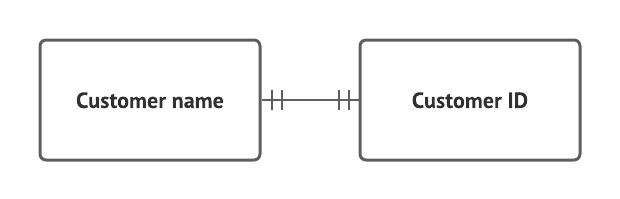
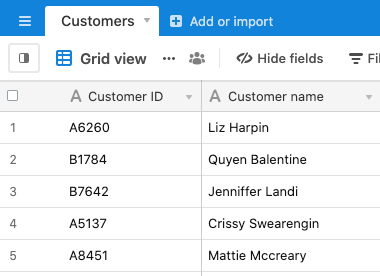
The simplest type of relationship in a relational database system is a one-to-one relationship. Two tables could have a one-to-one relationship, but more often than not, if you have a list of items that corresponds exactly to another list of items—for instance, a customer and a customer ID—it’s easier to display both sets of information in one single table:
One-to-many relationship

One-to-one relationships are nice and tidy, but alas, they are not as common as one-to-many relationships, where for each element in a list, you may be able to associate multiple elements from another list.
For instance, if you work with a company, you might have several contacts at that company. While each representative is attached to just one company, the company can have multiple representatives.
Many-to-many relationships
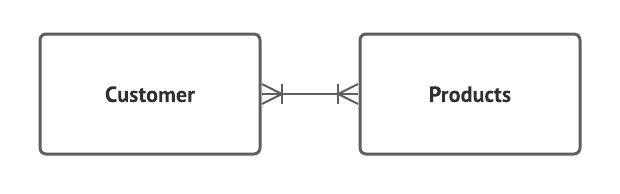
Now, things get crazy. Consider your list of customers and your list of products. A single customer might buy multiple products. And a single product is certainly purchased by multiple customers.
In this kind of case—probably the most common scenario—there are many ways to cross-reference information, and for this reason, a database that pulls records into various formats is the way to go. The trick to success is in the planning of the database design, or the schema.
What is a database schema?
As you architect your database, you create a structure with rules. This is called a schema. It’s the blueprint for your database that describes how you will store information, how that information will be related, and how a database administrator can work with it later.
A database schema allows you to enforce rules around data types. For instance, you might decide that a field only has three possible options, which you’ll input as strict choices. Or you might indicate that a field can only take text, or only numerals, or only an image file.
A database schema also enforces any rules you might have around relationships between tables: for example, if a school administration was using a database to plan classes, they could implement rules like "Each student must be signed up for at least two but no more than six classes," or "Each class requires at least one instructor."
These types of strict rules keep integrity within your database but help you achieve flexibility and scalability in how you present information to the outside world. For instance, with Airtable, you can display your data in different views and switch seamlessly between those views: grids, calendars, kanban boards, and galleries. Each view displays and lays out information from records to different ends.
You can also act on your database in tangible ways—for instance, creating Gantt charts or documents from database information, or using it in application development. Don’t want to build your own? Airtable has a variety of pre-built apps that help you enhance and enrich the information inside a database.
Now that you’ve gotten a tutorial on relational databases, how can you build one that helps you run your business?
Learn more here about how to get started designing an effective relational database.