Every organization works a little differently. Which means every organization has different needs for a database.
Want to learn the basics of database design? Check out Part 1 of our tutorial on designing effective databases, which will help you:
- define the purpose and objectives of your database
- build a list of database entities and attributes
- create a basic model for your database tables and fields
Once you’ve completed the above steps and put some fundamentals into place, you can start the process of linking all that database information together through relationships and rules.
In this blog, we’ll teach you how to establish relationships inside a database and explain the three types of table relationships (one-to-one, one-to-many, and many-to-many). Then we’ll delve into how to incorporate your organization’s unique business rules into your database design.
The result? A structurally sound database that works well for your company’s specific needs and real-world use cases.
This blog is Part 2 of our tutorial on designing effective databases. Haven't read Part 1? Check it out here.
Setting the table(s)
A critical step in designing any database system is to create a list of entities and attributes. An entity is an object, person, place, or idea—like “clients,” “products,” “projects,” or “sales reps.” Attributes are that entity’s defining characteristics, like “name,” “quantity,” “address,” or “type.” If entities are like nouns, then attributes are like the adjectives describing them.
A list of entities will become the tables in your database, and the attributes will become the fields for these tables.
Then you must choose the all-important primary key field (in Airtable it’s simply called the primary field), which uniquely identifies each record within a table. The primary key field must contain unique identifiers and should be a value that won’t need to be modified often.
How to establish table relationships
Once you’ve identified your tables, fields, and primary key fields, you can start the process of linking them all together.
This will be your preliminary attempt to define the logical relationships between your different tables.
Relationships between tables are created by linking together primary key fields and foreign key fields.
A foreign key is a field in one table that references the primary key of another table.
For example, if you were designing a sales pipeline database, your “Deals” table might contain a “Sales Rep” foreign key field, which would link to your “Sales Reps” table; if you were designing a content calendar database, your “Pieces” table might contain an “Editor” foreign key field and an “Author” foreign key field, both of which would link to your “Staff” table.
To start defining the relationships between your different tables, identify the potential foreign key fields. In an ideal relational database, foreign key fields are the only fields that should ever be duplicated, so if you identify any fields that appear in multiple tables, those are likely candidates for foreign key fields.
The three types of table relationships
There are three types of relationships between tables:
- One-to-one relationships, in which a record in one table is related to a single record (and only that record) in another table. An example of this might be an IT team’s asset tracking database with an “Employees” table and a “Computers” table: each employee only possesses one company-owned computer, and each company-owned computer is possessed by only one employee. (Note that one-to-one relationships are relatively uncommon.)
- One-to-many relationships, in which a record in one table can be related to one or more records in a separate table. An example of this might be a project tracker database which contains a “Projects” table and a “Tasks” table: each project has multiple associated tasks, but each task is only associated with one project.
- Many-to-many relationships, in which one or more records in one table can be related to one or more records in another table. An example of this might be an inventory of books, which contains a “Titles” table and an “Authors” table: each title will have been written by one or more authors, and each author can have written one or more books.Being able to identify each relationship type is helpful for modeling your organization’s business rules. For example, if you specifically define a relationship as one-to-many, you can enforce a rule that the records on the “many” side of the relationship can, indeed, only ever be linked to one record in the other table.
You might be wondering why you would want to go through the effort of establishing the relationships between these tables. The main reason is that the table relationships actually allow you to make logical connections between pairs of tables, which in turn allows you to draw data from multiple tables simultaneously.
Being able to draw data from related tables simultaneously means that you can make your tables more efficient and minimize redundant data. If you construct the relational model between tables appropriately, you can see whatever data you need to see from any table, at any time, but you’ll only ever need to enter it or modify it in a single location.
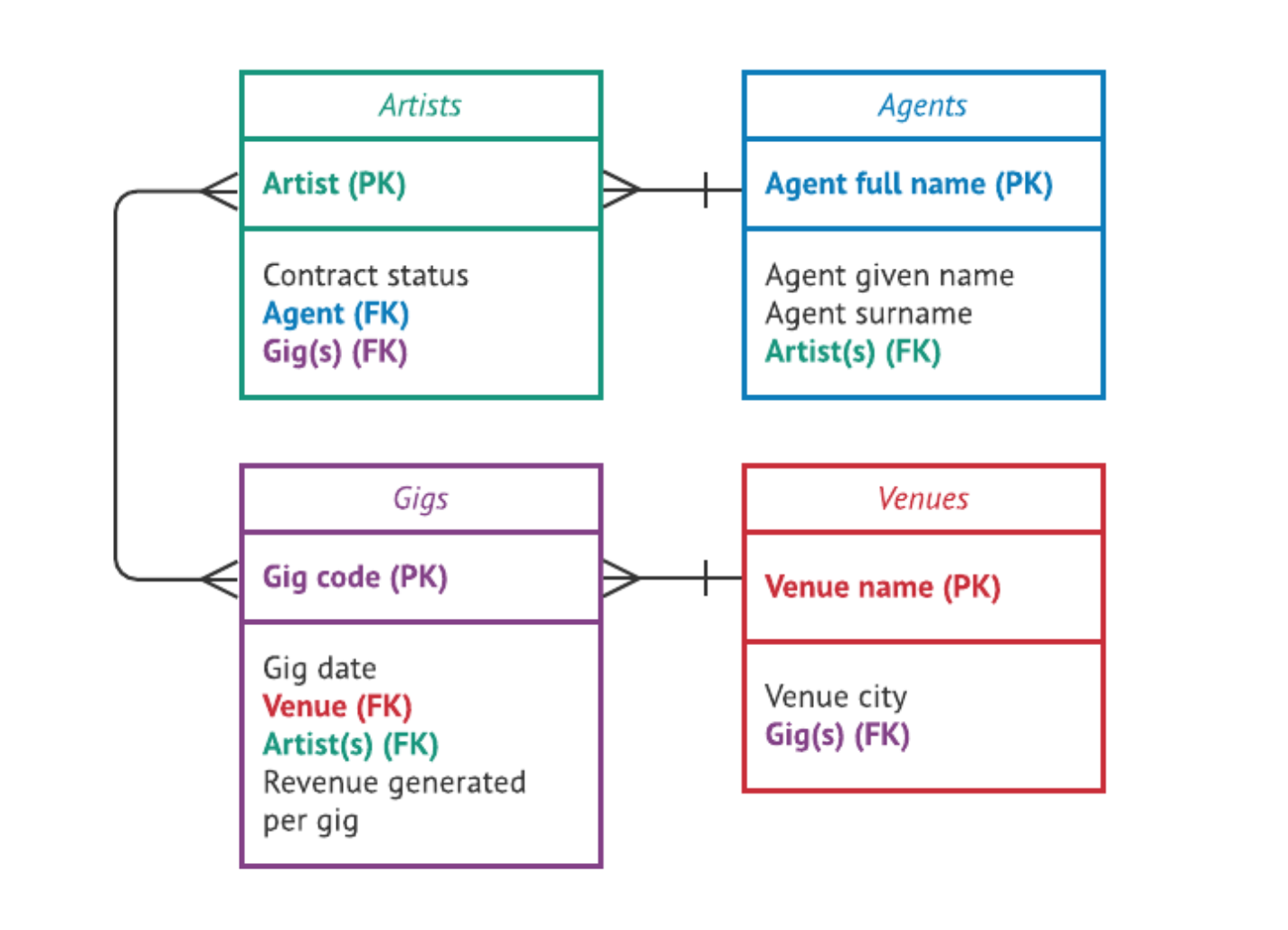
To better understand how this might work in practice, let’s suppose we’re running a talent agency. We want to look into our database and see at a glance how much revenue each artist at the agency has generated in total across all gigs. The first table would be for “Gigs” and we’d need a second table for “Artists.” Then we could use that relationship to look up data from all the relevant gig records per artist.
Then we would create a new computed field in the “Artists” table—“Total gig revenue”—that sums the total value of “Revenue generated per gig” for all linked records in the “Gigs” table per artist.
A computed field is a special kind of field that automatically generates a value using one or more values from another field in the database. Because the computed field updates automatically, if you ever edit a value in the “Revenue generated per gig” field or add any new gig records for a particular artist, the “Total gig revenue” field will also update automatically.
You can even take this one step further: if you wanted to see how much revenue each agent has generated in total through all the artists they manage, then you could use the established relationship between the “Artists” and the “Agents” table and create a new computed field in the “Agents” table—“Artists’ total gig revenue”—that sums the total value of “Total gig revenue” for all linked records in the “Artists” table per agent.
Since this new computed field in the “Agents” table is connected to the “Gigs” table via the “Artists” table, it will also be updated automatically if the values in the “Gigs” table change, even though there is no direct relationship between the “Gigs” and “Agents” tables.
One activity that can be very helpful for visualizing how to configure your tables is creating an entity-relationship diagram, or an ER diagram.
An ER diagram is a kind of chart that uses shapes to represent your tables and lines to represent the relationships between your tables.
How to establish business rules
After fully establishing the overall structure of your database, it’s time to incorporate your organization’s unique business rules into your database design.
Because business rules are so closely tied to the specific ways in which your organization does its work, your most valuable resource in figuring out which type of database to build will be managers and end users at that organization. Consulting with them can provide invaluable insight into how your company intends to store data, what sorts of functionality your database needs, and which constraints will be the most impactful for your workflows.
Generally speaking, there are two main kinds of business rules.
Field-specific business rules refer to constraints placed on specific fields. Some examples of field-specific business rules might be “Dates on our app invoices must be displayed in this data type and format: ‘2020-12-22.’” Or: “Email addresses stored in the employee directory must never be null and must be valid email addresses,” or “The only valid values that can be selected for this status field are ‘To do,’ ‘Doing,’ and ‘Done.’”
Relationship-specific business rules, which we briefly touched on earlier, refer to constraints placed on table relationships. Some examples of relationship-specific business rules might be “Each project in our video production tracker must be linked to one or more fact-checkers,” or “Each line item in a customer’s order must be linked to one and only one product.”
The most thorough method of identifying and implementing your field-specific business rules is to systematically review each field within each table to determine which business rules apply to that field.
Every field will have some relevant business rules, even if those rules are as general as “Every value in the ‘Employee first name’ field should be a string composed of letters.” In a similar fashion, you can systematically review each of the relationships in your proposed database structure and assess whether or not they require any relationship-specific business rules.
In the future, you will probably need to change your existing business rules or add new ones to the schema. For example, your team might decide that “Canceled” should be a valid potential value for a task status field that currently includes only “To do,” “Doing,” and “Done” as options.
Fortunately, if you have followed the previous steps and set up a robust underlying database structure, it should be relatively easy to adjust your field- and relationship-specific business rules down the road without having to restructure your entire database.
What’s the difference between a database and a spreadsheet? Read our guide.